大数据实时处理框架与数据处理服务简述
随着数据规模的爆炸式增长和业务对时效性要求的不断提高,大数据实时处理已成为现代数据架构的核心组成部分。它旨在对持续产生的数据流进行即时分析、计算与响应,以支持实时监控、智能推荐、风险预警等关键应用场景。本文将简述主流的实时处理框架及其背后的数据处理服务生态。
一、核心实时处理框架
实时处理框架是实现低延迟数据计算的技术引擎,主要分为两大类:
- 流处理框架:
- Apache Flink:当前公认的领先者,提供了高吞吐、低延迟、Exactly-Once语义的精确状态计算能力。其核心优势在于将批处理视为流处理的一种特例(有界流),实现了真正的流批一体,简化了架构。
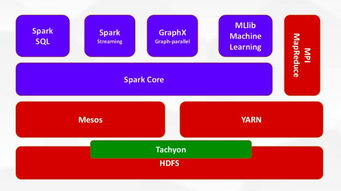
- Apache Spark Streaming:基于微批处理(Micro-Batch)模型,将实时数据流切分成小批次,然后利用强大的Spark引擎进行处理。虽然延迟略高于纯流式框架,但其与Spark生态的无缝集成、丰富的API及成熟的稳定性,使其在众多场景中仍被广泛应用。
- Apache Storm:早期的纯流式处理框架,延迟极低,但编程模型相对复杂,且对状态管理和精确一次语义的支持不如Flink完善。
- Apache Kafka Streams:一个轻量级的客户端库,专为处理存储在Kafka中的数据而设计。它允许应用程序直接消费、处理并生产回Kafka主题,无需部署独立的处理集群,非常适合构建微服务化的实时流处理应用。
- 流式SQL与声明式框架:
- 随着技术的发展,更高层次的抽象变得流行。Apache Flink SQL、ksqlDB(基于Kafka)等工具允许开发者使用标准的SQL语句来定义流处理逻辑,大大降低了开发门槛,提升了开发效率。
二、数据处理服务:云原生与平台化
为了降低企业自建和维护复杂实时处理集群的成本与难度,各大云厂商和平台提供商推出了全托管的数据处理服务。这些服务将底层框架封装,提供开箱即用的能力:
- 核心价值:
- 无服务器化与弹性伸缩:用户无需关心服务器资源,服务可根据数据流量自动扩缩容,按实际使用量计费。
- 全托管运维:平台负责集群的部署、监控、升级、故障恢复和安全补丁,极大减轻了运维负担。
- 生态集成:与云上的数据存储(如对象存储、数据仓库)、消息队列(如Kafka服务)、计算引擎等深度集成,形成端到端的解决方案。
- 企业级功能:内置高可用、安全管控、权限管理、作业开发与调度平台等。
- 典型服务举例:
- 阿里云实时计算Flink版:基于Apache Flink的完全托管服务。
- 亚马逊云科技Amazon Kinesis Data Analytics:支持使用SQL或Flink应用处理Kinesis数据流。
- 微软Azure Stream Analytics:以SQL查询语言为核心的完全托管实时分析服务。
- 谷歌云Dataflow:基于Apache Beam模型,提供统一的流批处理托管服务。
三、
大数据实时处理技术栈正朝着流批一体、SQL化、云原生化的方向快速发展。选择技术方案时,需综合考虑业务场景的延迟要求、数据规模、团队技能栈和运维成本。对于追求极致灵活和控制力的团队,开源框架(如Flink)是强大基础;而对于希望快速构建、专注业务逻辑的企业,采用云厂商提供的全托管数据处理服务往往是更高效、更经济的选择。两者共同构成了支撑当下数据驱动业务创新的坚实基石。
如若转载,请注明出处:http://www.wsxerb.com/product/12.html
更新时间:2026-06-19 02:41:15